

- Published on
Unlocking the Secrets of GPT: A Deep Dive into the inner workings of the AI Revolution
Introduction
What is GPT?
GPT stands for Generative pre-trained transformer. It is a type of neural network model that uses transformer architecture and is pre-trained on a large corpus of text to generate new text and also fine-tune specific tasks (by using the former pre-trained model) by using less data and the ability to learn general features of a language.
In simple terms, it is a neural network with pre-initialized parameters that you can use to perform most NLP tasks. That is, instead of developing your own neural network model you can use this to fine-tune according to your task.BERT also does the same but the only difference between these two is the Model's architecture and training details.
Nevertheless of the above technical jargon, OpenAI GPT’s indirect statement is “use their pre-trained model” to perform your NLP tasks such as speech recognition, text summarization, etc…
How GPT works
Let’s start dissecting the working principles of this GPT. At a glance we can say that OpenAI GPT has gone through two phases:
- Unsupervised pre-training
- Supervised fine-tuning
Phase 1: Unsupervised pre-training
Let’s get to the business by exploring the answer to the following questions:
Datasets that were collected for the sake of training the model
--> What datasets were used to train OpenAI GPT?
- Bookcorpus Dataset
“It contains over 7,000 unique unpublished books from a variety of genres including Adventure, Fantasy, and Romance. Crucially, it contains long stretches of contiguous text, which allows the generative model to learn to condition on long-range information”
Note: Although there could be other datasets used to train GPT, researchers don’t often reveal them because of copyright claim apprehension.
--> How are they preprocessed/cleaned?
- Ftfy library: To clean raw text in BooksCorpus
- spaCy tokenizer: Standardize some punctuation and whitespace
Model Architecture

→ What is the shape of the input that model processes?
The shape of the input that you need to design to feed into the pipeline of the GPT model is [batch_size, sequence_length, features_size]
where batch_size is 64 (randomly sampled), Sequence_length = 512 tokens, Features_size = 768
Note on batch_size:
- The “batch_size” is the number of sequences of text that are presented to the model at once. In simpler terms, the number of 2d matrices as you can see in the above image.
- The batch size is also a hyperparameter and can be set during model configuration, it’s typically a multiple of 2 like 2, 4, 8, 16, 32, etc.
- The batch size is a trade-off between the amount of memory required (RAM) and the efficiency of the computation. The larger the batch size, the more memory is required, but the computation can be more efficient
Note on Sequence length:
- The “sequence length” is the number of words in a given sequence of text that is input to the GPT model. Also a hyperparameter
Note on Features size:
- Refers to the dimensionality of the word embeddings (word in vector representation).
- Word embeddings are numerical representations of words that capture their meanings in a high-dimensional space.
- The dimensionality of these embeddings is a hyperparameter that is set during the model’s configuration.
→ What are the types of layers used for the model, basically, the model’s configuration?
Prior Info you should know:
There is a new neural network architecture named “Transformers” introduced in 2017 presented in the “Attention is all you need” paper aiming to improve the performance of machine translation tasks in NLP. It was a revolutionary thing that happened in the NLP field. Soon after its introduction, many NLP researchers have been using this transformer instead of traditional RNNs, LSTMs, or GRUs for performing all kinds of NLP tasks and achieving SOTA results (chatGPT is one of its byproducts which is revolutionizing the world right now!!)
Gentle Introduction to Transformers
Transformers is based on encoder-decoder architecture. Typically, it is used for machine translation tasks ( let’s say French to English). An encoder takes in a vector representing a word in French and spits another vector representing what it has learned from that vector. The decoder takes that vector as a part of its process and outputs another vector representing a word in English.
Want to know more about this intriguing “Transformers”? The best blog I have read personally is this. Illustrated Transformer
The following picture represents GPT's architecture as provided by OpenAI in their research paper:

This GPT uses decoder-only transformers. So, to answer the question about “types of layers used by the GPT architecture”,
- GPT uses a masked multi-head self-attention layer
- Then after, it has a position-wise feedforward neural network with Dense Layers stacked along the path.
- The above two things are condensed into one block which they address as a “Decoder” Block.
- GPT uses 12 of these Decoder blocks in their architecture
→ Which activation function for each layer did they use to activate the neurons?
Gaussian Error Linear Unit (GELU)
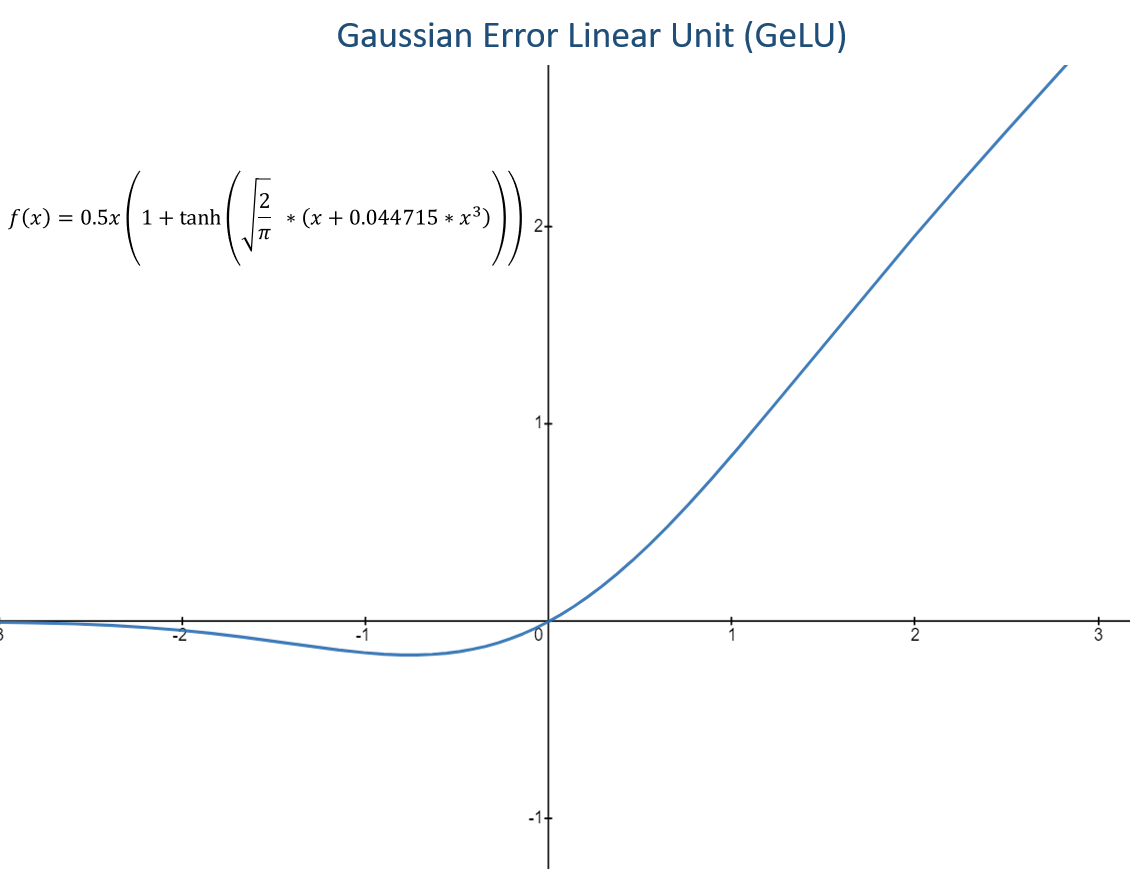
→ How the output layer is represented i.e., the output of the model is structured?
The size of the output layer is (vocab_size, 1). In other words, the number of neurons in the output layer is equal to the number of unique words/tokens present in the dataset.
Hold on, there’s something more you have to know in here. GPT uses a byte pair encoding (BPE) vocabulary with 40,000 merges. Basically, this reduces the size of the vocabulary.
→ How the input goes and converted to output step-by-step illustration through matrices or some equations or pictures?
Let us understand this through one data sample i.e., by taking one matrix of size [sequence_length, features_size] (say [5, 5])
Step 1: Adding position embedding matrix to the embedding matrix
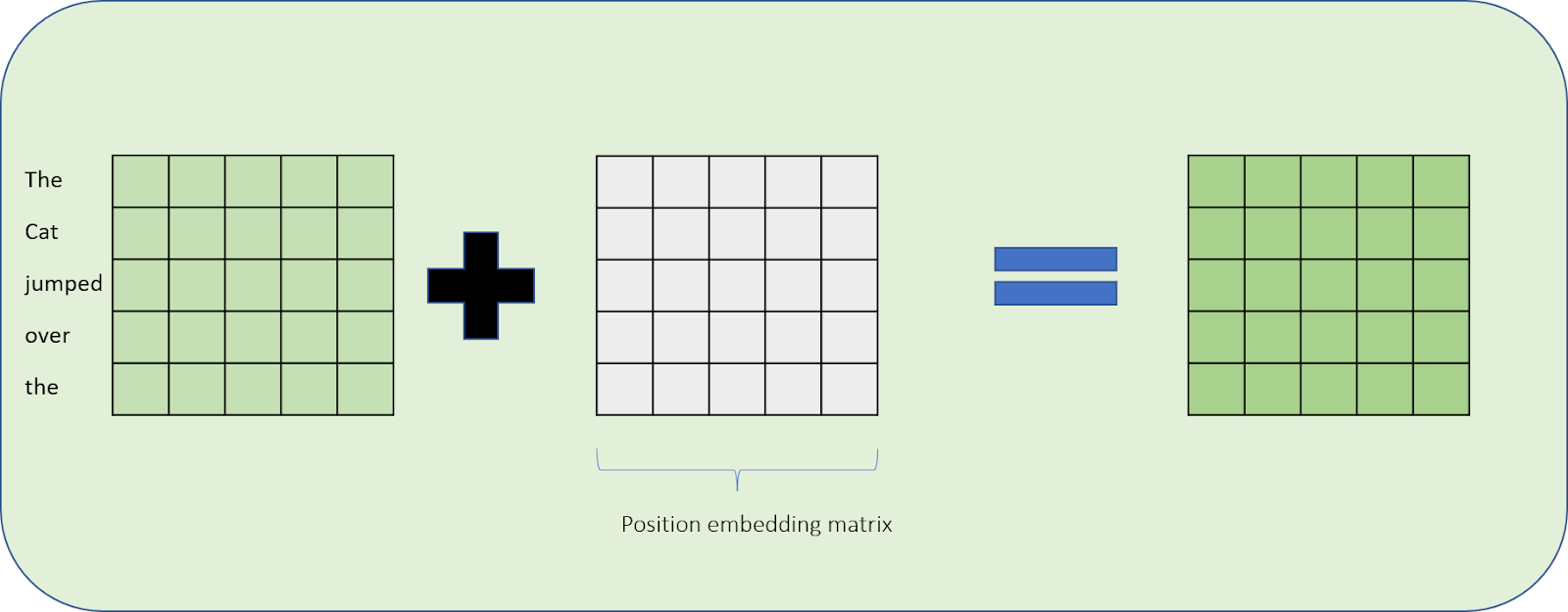
“We used learned position embeddings instead of the sinusoidal version proposed in the original work.”
Step 2: Pass the obtained matrix through the Masked Multi-head self-attention layer and apply residual connection as shown in the image below.
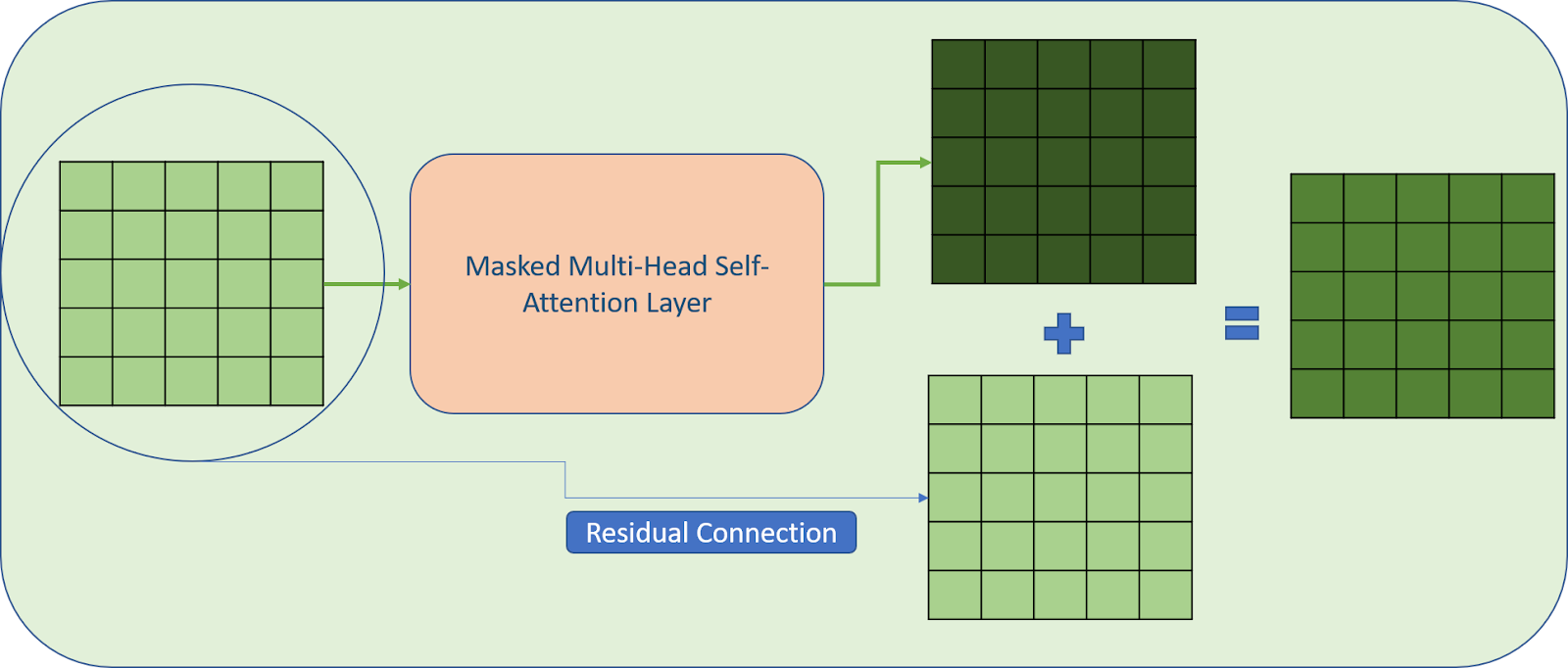
“Masked self-attention heads (768-dimensional states and 12 attention heads)”. This means the output shape is [batch_size, sequence_length, 768]
Note: Here input size i.e., [batch_size, sequence_length, features_size] is equal to the output size of the masked multi-head self-attention layer i.e., [batch_size, sequence_length, 768]. This makes sense because we can add both of these during residual connection only if their sizes are equal.
Meaning of “Masked” and “12 Attention Heads”:
To understand this thoroughly, you have to know how the self-attention layer works. I’ll suggest you go through Illustrated Transformer to get the meaning of these terms and also to understand the working of the self-attention layer. Come back once you’re done.
Step 3: Apply layer normalization to the resultant matrix

Step 4: Apply Position wise Feed-forward networks along with the residual connection as shown in the below image
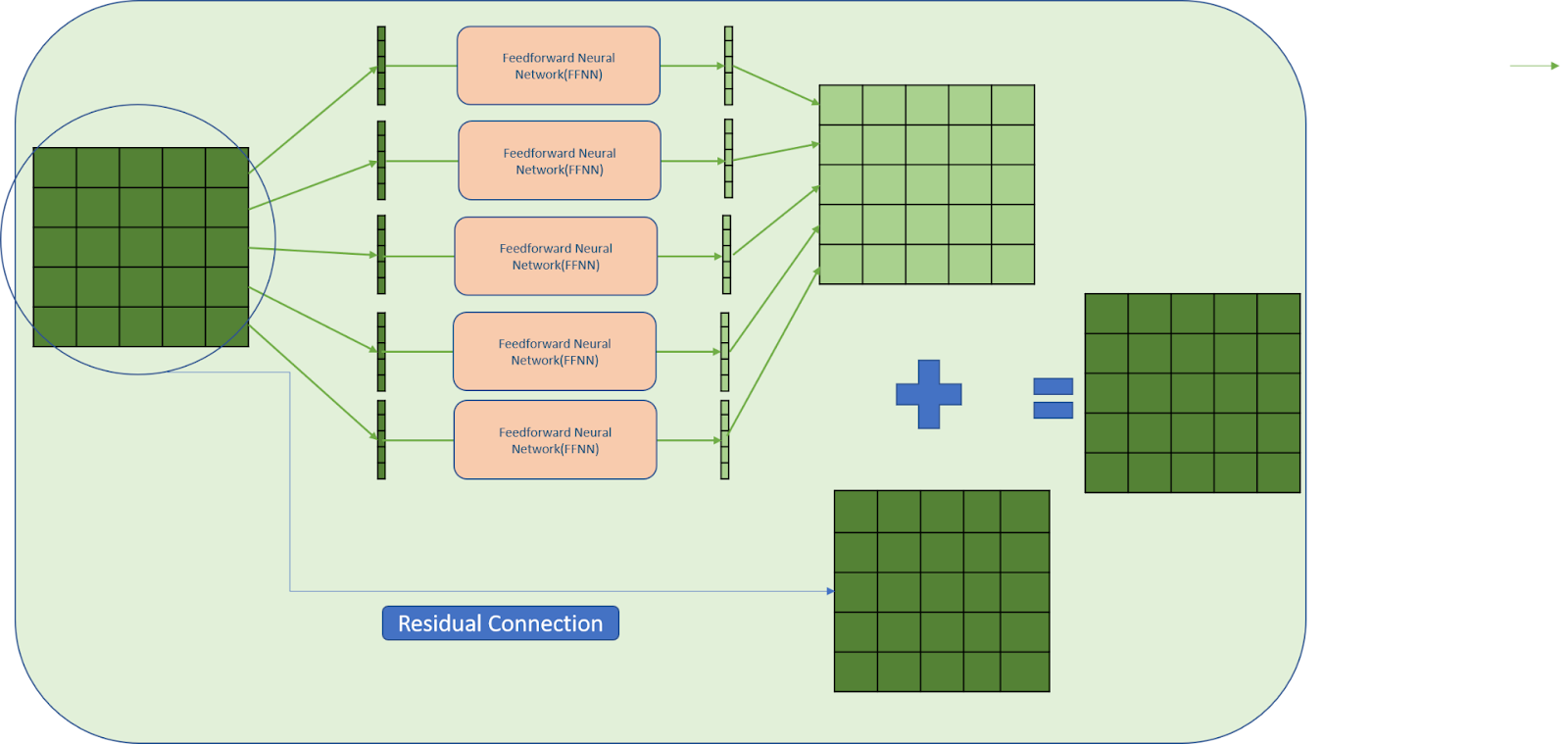
The size of hidden states OpenAI’s GPT is 3072. That means the hidden state is of the following shape (3072, 1) inside these feed-forward neural networks. But the number of hidden layers is unknown.
Step 5: Apply Layer Normalization and again pass the obtained matrix through the other decoders as well. Note the resultant matrix obtained at the end of the decoder block is of the same shape as the input.

OpenAI’s GPT uses 12 of these Decoder blocks and at the end uses “Linear + Softmax Layer” to make the predictions.
Training Details of the Model
→ In how many batches do the training data given to the model?
As we have already mentioned, the batch_size is equal to 64 (randomly sampled)
→ What is the choice of the loss function that calculates the error between the model’s output and actual output?
The loss function used in OpenAI's GPT is the cross-entropy loss. It is used to measure the difference between the predicted output distribution and the true output distribution. The cross-entropy loss is a common choice for training language models because it is well-suited to modeling discrete data, such as words in a sentence.
→ What is the choice of the optimization algorithm (includes studying of learning rate as well) used to update the weights (parameters) during backward propagation?
Backpropagation Algorithm → Stochastic Gradient Descent Algorithm
Optimization scheme → Adam Optimizing scheme with a max learning rate of 2.5e-4
- The learning rate was increased linearly from zero over the first 2000 updates and annealed to 0 using a cosine schedule.
Additional Details of the Model
- The model is trained for 100 epochs on mini-batches of 64 randomly sampled, contiguous sequences of 512 tokens.
- Weight Initialization of N(0, 0.02) (because of layer norm)
- Dropout layers across the residual connection, embedding, and attention layers with a rate of 0.1 for regularization
- A modified version of L2 regularization with w = 0.01 on all nonbias or gain weights.
Graphs illustrating the results
→ How is it performing compared to the existing models?

The above graph illustrates the comparison between how this Transformed based pre-trained model vs the LSTM network performs against different tasks like sentiment analysis, Winograd schema resolution, linguistic acceptability, and question answering.
A Note on the above results:
You should observe that the model is directly used on the aforementioned tasks instead of using supervised learning to fine-tune the model. We generally call this type of assertion as “Zero-shot performance” of the model.
Finally, you can play with this model which comes with a “transformers” package by using the following simple piece of code and is available for you to try here: OpenAI GPT Model
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='openai-gpt')
set_seed(42)
generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)