

- Published on
Exploring GPT-3: A Comprehensive Illustrative Guide to the AI Behind ChatGPT (Part 2)
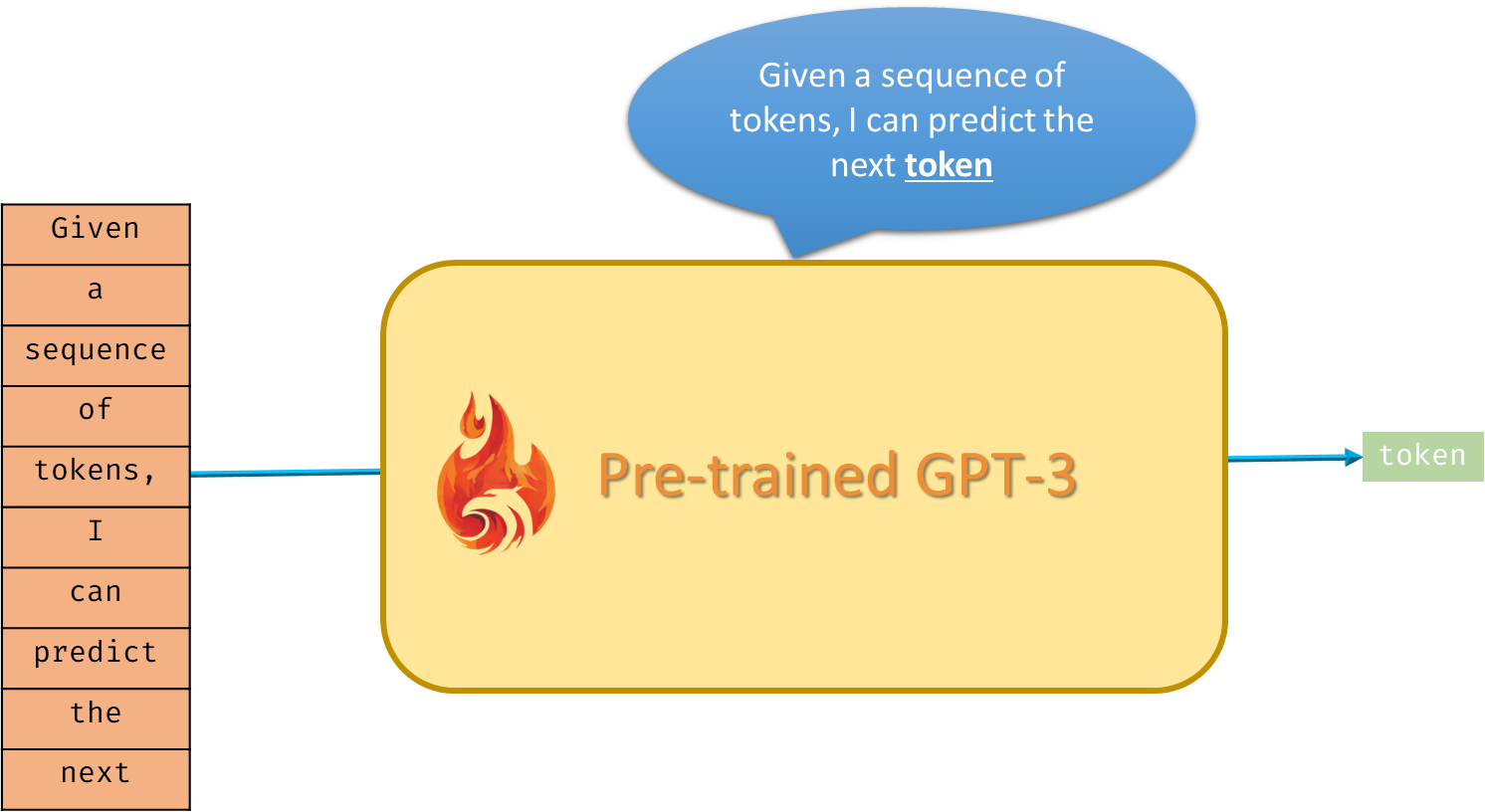
Table of Contents
Let’s think about this pre-trained GPT-3 model in a broad way. This gigantic model was trained on a large corpus of text where the objective of self-supervised learning is just to predict the next token (not the “next word”) given a sequence of tokens.
Now, how on earth are we going to make this model (which predicts the next token given a sequence of tokens) yield any fruitful results? For example, in a Q&A task if asked the question “What is meant by this?” this pre-trained GPT-3 model won’t even get our intention in the first place!
Here are a couple of examples provided by OpenAI regarding this issue:

As you can see, the pre-trained GPT-3 model’s task i.e., text completion is really unpredictable. Sometimes it is trying to give an answer and sometimes it’s writing even more questions given a question as an input sequence. What do we do then? How can we perform text summarization or any other NLP task with this naive pre-trained GPT-3 model?
Well, fortunately, we’ve three options to make the model do what we want.
- Featured-based Transfer Learning
- Fine-Turning the Pre-trained GPT-3 model
- Few-shot Learning
Feature-based Transfer Learning
Feature-based transfer learning is transferring some layers out of the pre-trained GPT-3 into a new task-specific architecture. In mathematical terms, we build a totally different model architecture for our specific task let’s say text summarization but what we do is we take features i.e., weight and bias matrices from some layers, and initialize our weight and bias matrices with them in our new model’s architecture and typically they are not updated during training meanwhile other layers which are not pre-initialized will.
It’s ok if the above paragraph doesn’t make sense. I remember the first time I came across this concept when I tried out word2vec embedding weights for an image-to-text generation model instead of training and updating my embedding weights from scratch. And I set trainable=False (I implemented it in Keras) so that those word2vec embedding weights won’t be updated during training. This is one of the examples of featured-based transfer learning. Note that you can borrow any number of layer weights matrices for your task-specific designed model. You’re going to see an illustration that tries to explain this concept in a better way.
Fine-Tuning the pre-trained model
Fine-Tuning (FT) has been the most common approach in recent years and involves updating the weights of a pre-trained model by training on a supervised dataset specific to the desired task. Typically thousands to hundreds of thousands of labeled examples are used. The main advantage of fine-tuning is strong performance on many benchmarks. The main disadvantages are the need for a new large dataset for every task, the potential for poor generalization out-of-distribution, and the potential to exploit spurious features of the training data, potentially resulting in an unfair comparison with human performance.(Source)
In simple words, Here we train the pre-trained model itself instead of designing a task-specific model architecture with a supervised (human-labeled) dataset. Weights are updated accordingly to align with the patterns of that dataset.
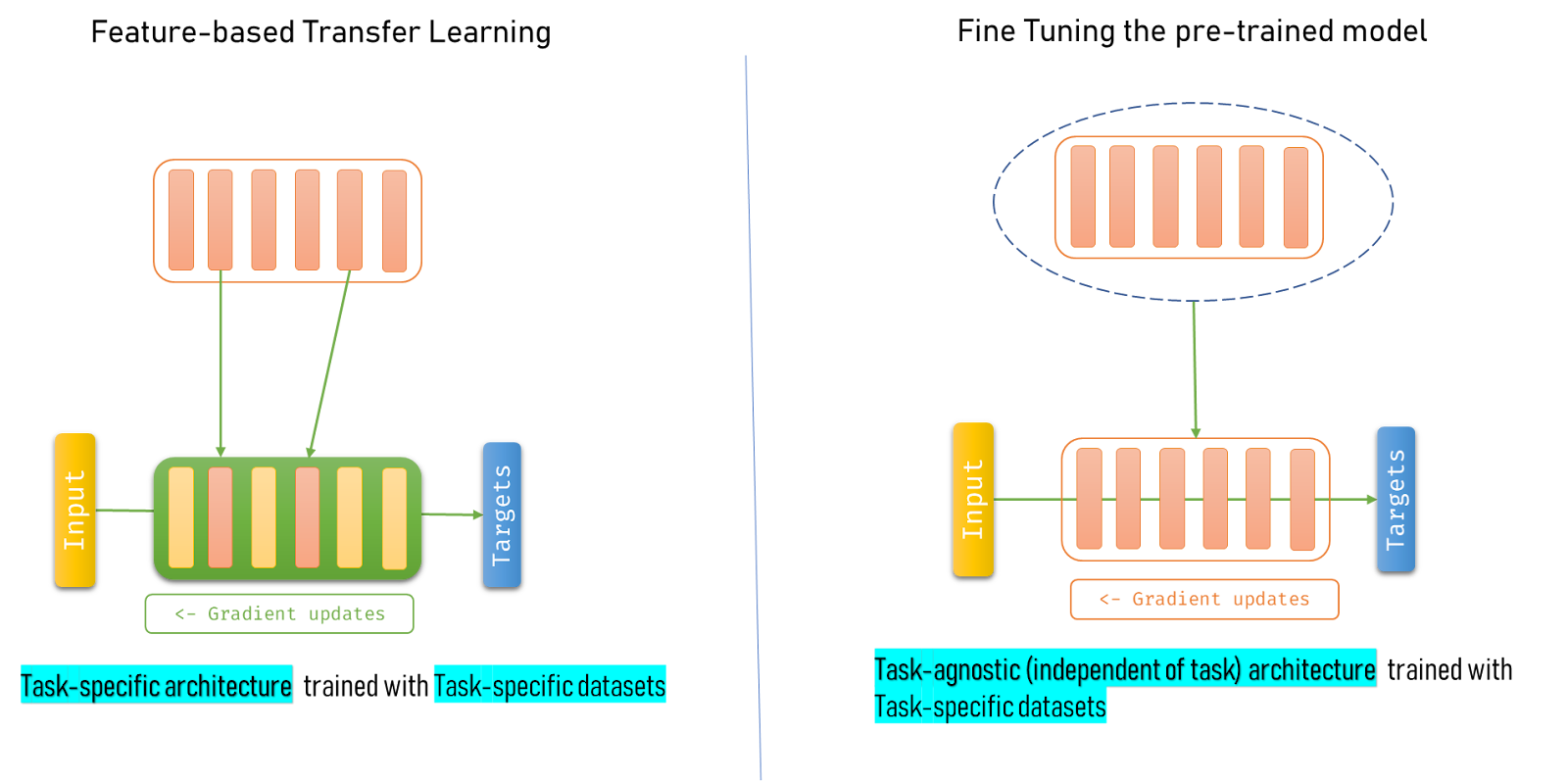
Hence fine-tuning a pre-trained model is a better choice compared to featured-based transfer learning. Indeed, this is the trend for transfer learning (meaning using either the entire pre-trained model (fine-tuning) or some of their layers(feature-based) as a starting point) over the years as mentioned by OpenAI GPT-3 in their research paper.
Recent years have featured a trend towards pre-trained language representations in NLP systems, applied in increasingly flexible and task-agnostic ways for downstream transfer. First, single-layer representations were learned using word vectors and fed to task-specific architectures, then RNNs with multiple layers of representations and contextual state were used to form stronger representations (though still applied to task-specific architectures), and more recently pre-trained recurrent or transformer language models have been directly fine-tuned, entirely removing the need for task-specific architectures.
Downsides of Fine-Tuning
Problem 1: Need for a large dataset of labeled examples for every new task
Although we didn’t need to build a neural network model from scratch, there is a need for collecting hundreds to thousands of examples to fine-tune the pre-trained GPT-3 model for every specific task. For many NLP tasks, it is difficult to collect a large supervised training dataset, especially when the process must be repeated for every new task.
Problem 2: Poor Generalisation
As models become more powerful and capable of capturing more complex relationships in data, they also become more susceptible to exploiting random correlations that exist in the training data but may not generalize to new, unseen data. This is often referred to as overfitting.
When the training data has a narrow distribution, representing a limited range of possibilities, a complex model is more likely to fit the noise in the data, rather than the underlying patterns relevant to the task at hand. This can result in poor generalization performance, as the model may perform well on the training data but poorly on new, unseen data.
Problem 3: Humans don’t need hundreds or thousands of examples for a specific task.
As humans, we do not need a huge number of examples to answer an unseen task. A brief directive in natural language (e.g. “please tell me if this sentence describes something happy or something sad”) or at most a tiny number of demonstrations (e.g. “here are two examples of people acting brave; please give a third example of bravery”) is often sufficient to enable a human to perform a new task to at least a reasonable degree of competence.
Basically, NLP has been through featured-based transfer learning to a fine-tuning a pre-trained pattern. But how on earth can we overcome the disadvantages of fine-tuning this time? (Is it possible entirely?)

An Innovation to our rescue: Few-Shot Learning
Before jumping straight into the details, I will try to give a cinematic intro for this few-shot learning.
Firstly, given the vast number of parameters, GPT-3 can meta-learn. Initially, it was confusing for me to learn what exactly this meta-learning or in-context learning is all about and how it works in the first place. Since they mentioned that in in-context learning (you can replace the word with meta-learning as well) the model will learn without any gradient updates. I was clueless about this particular thing (What!! How come learning is possible for a specific task without gradient updates?).
Following up, I thought the model doesn’t know anything except it can understand nuances of the language i.e., the ability to predict which token comes next after a sequence of tokens. I'm terribly wrong about this theory!! During pre-training, this GPT-3 implicitly has seen a lot of things from Wikipedia pages, academic papers, and Reddit posts to Shakespeare’s works. We can hypothesize that training on this text allows the LM to model a diverse set of concepts. So, Implicitly the model has seen a wide variety of NLP tasks maybe sometimes tied in a sequence or set of sequences.
Finally, this has raised a beautiful thought among AI researchers. Let’s break down those details step by step now.
Inference 1: The transformer decoder model is an autoregressive model in the first place.
What does it mean by an “autoregressive model”? Given a sequence to our GPT-3 model, the model is trained not only to predict the next token for the sequence, indeed it repeats that task implicitly among its sequence.

So, when given a sequence of tokens (not necessarily "words") as input, the GPT-3 model implicitly repeats the task of predicting the next token in the sequence for each subsequent token in the input sequence, which is what makes it an autoregressive language model.
Inference 2: Definition of meta-learning/in-context learning
The term “learning” is a deceptive one in meta-learning or in-context learning. Actually, we’re not even going to make the pre-trained GPT-3 model learn anything in few-shot learning in contrast to feature-based and fine-tuning(where gradient updates happen). Note we say we improvised/made the model learn when there are gradient updates applied.
Definition: During unsupervised training, a language model develops a broad set of skills and pattern-recognition abilities. Meta-learning, also known as learning to learn, refers to the process of using previous learning experiences (important) to improve the efficiency and effectiveness of future learning. In other words, GPT-3 looks at its training data and generalizes to new tasks without any gradient updates.
Meta-learning can be seen as a form of in-context learning, which involves learning how to learn within a specific context or domain. In-context learning refers to the ability to adapt and transfer knowledge and skills to new situations, rather than just rote memorization or isolated skill acquisition.

In simple tone, due to the autoregressive nature of decoder-only transformers, the in-context learning (learning that happens implicitly in a sequence block) occurs during pre-training phase of GPT-3.
Inference 3: Meaning of few-shot learning
By now, you must have understood what a sequence block is. “GPT-3 has a sequence block of size 2048” should make sense to you i.e., a sequence of 2048 tokens where implicit autoregressive training happens among successive tokens.
What if add a default set of tokens about the NLP task and may a few examples followed by the task description to the set of test tokens? Something remarkable happens here and which were are referring to a one-shot (if one example is included after the NLP task description), zero-shot (if no example is included) and few shot ( a few examples of context size 10 to 100 (tokens) after task description is included) learning.

This is what this pre-trained model has gone through instead of getting trained (gradient updates) again. After pre-training this GPT-3 model here we’re triggering the previous learning experience of the model by providing an NLP task description and some examples, given its peculiar capability of learning and recognizing patterns in its training dataset. (Give this sentence a read again if you’re still confused)
Tuning NLP task datasets to make them edible to token-by-token predicting GPT-3 model
Finally, you can end skimming through this blog by exploring the answer to one last question. That is,
How to prepare a dataset for this model in the first place? For example, if we have a Q&A dataset how can we feed that question-and-answer pair into a model that can only take a sequence of tokens and predicts one single token that comes after? Well, rather than explaining here’s the picture presenting the final answer.
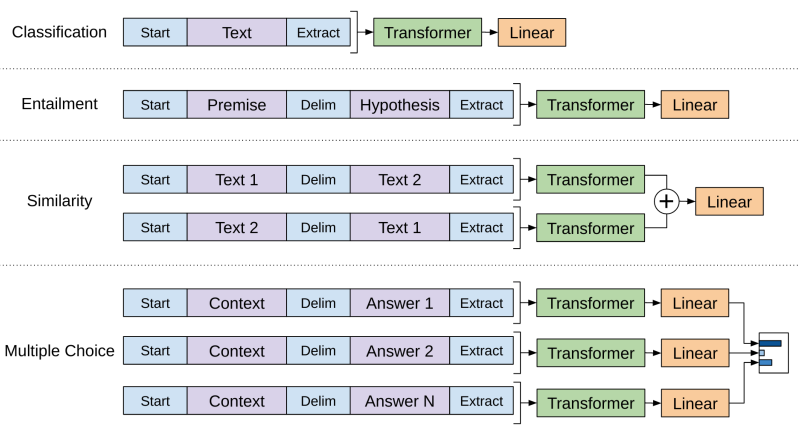
Here all structured inputs are converted into token sequences to be processed by our pre-trained model.
Do you know? Whatever the task might be, the maximum number of tokens that this model can generate is equal to the sequence length. This should make sense since we want to predict by considering every token. So, when you type in a prompt in ChatGPT the maximum number of tokens generated from both question and answer combined is equal to 2048. After that, you will see your answer get cut off.
Visualizing Results (Just a few)
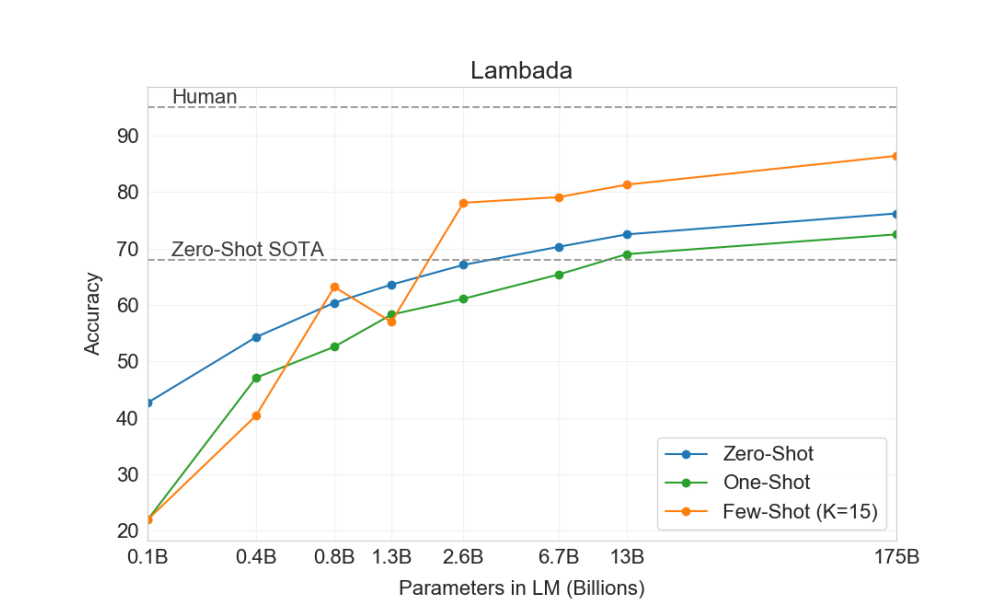
I’ll leave with this one thing for you to ponder on: In-context learning (learning during pre-training) can be improved by trying out these 4 ways as pointed out in PaLM research paper:
- Scaling the size of the models in both depth and width
- Increasing the number of tokens that the model was trained on
- Training on cleaner datasets from more diverse sources
- Increasing model capacity without increasing the computational cost through sparsely activated modules.